
はじめまして。プラットフォームソリューション部の山口です。
今回は、昨年2022年末にReader Store(運営:株式会社ソニー・ミュージックエンタテインメント)にてリリースされた「似た商品を探す」の裏側について紹介します。
(現在は、コミックのみで利用できる機能です。)
機能
まずは、「似た商品を探す」機能について簡単に紹介します。
簡単には、「○□ぽい本」、「□○みたいなテイストの本」 を見つけることができる機能と考えています。
現在は、あるコミックの要素を算出して、その要素と近しい作品たちが一覧となって表示されます。
例えば、幕末を舞台にしたバトルマンガであれば、そのマンガは「幕末」「バトル」「刀剣」などの要素が強いだろうと算出します。
そして、それらの要素の傾向を持っているマンガを算出しています。
このあたりは実際に、Reader Store
にて好きな、 もしくは興味のあるマンガを検索し、
「似た商品を探す」を使っていただけるとわかりやすいですので
よければ一度利用してみてください。
類似性とシステム
さて、ここからはよりシステム的な面での機能説明や裏側のことについて紹介していきます。
次のような区分にわけて説明します。
- 要素の抽出と類似性について
- 検索方法とシステム構成
要素の抽出と類似性について
「似た」と一口に言っても、どう似ているのか、どの程度似ているのかなど気になることがあります。
その点をシステム的にどう算出し、どう表現するのかをまずは説明します。
本を構成する要素は多分にありますが、どんな本であるかがわかる1つの要素として「あらすじ」や「説明文」があります。
今回は、「説明文」に絞って説明します。
説明文を1つとっても使われている言葉・単語や表現は多岐に渡ります。
我々はまずWord2Vecなどの機械学習アルゴリズムを利用して、この表現方法を学習し、ベクトル化することを行いました。
例えば、次のように説明文を利用して、ベクトルを算出しました。
- マンガA ならば (0.1, 0.2, 0.3)
- マンガB ならば (0.3, 0.1, 0.6)
この時点でも、このベクトルを利用することで、似た作品の算出はできますが、「何故似たのか」「どこが似ているのか」がわかりません。
そのため、「バトル」「刀剣」などの要素についても同様にベクトル化を行い、
本ごとにどの要素と類似しているのか(その要素を持っているのか)を算出できないかと考えました。
「バトル」「刀剣」などの要素のベクトル化は、本の説明文のベクトル化と同様の手法で算出しました。
例えば、次のようにです。
- バトル ならば (0.0, 0.0, 0.9)
- 刀 剣 ならば (0.3, 0.1, 0.0)
これで、本のベクトルと要素のベクトルが算出されました。
次に、「本ごとにどの要素と類似しているのか」を算出します。
この算出にはいろいろな手法があります。
例えば、ユークリッド距離やCosin類似度などです。
今回は、簡単にL1ノルムを利用して、「マンガA」と「バトル」との距離を出してみます。
| バトル | 刀剣 | |
|---|---|---|
| マンガA | 0.9 | 0.6 |
| マンガB | 0.7 | 0.6 |
例えば、マンガAは「バトル」が0.9、「刀剣」が0.6とバトルが強い作品だろうと算出します。
また、マンガAとマンガBは「バトル」の要素を強くもち、「刀剣」については同程度触れている作品だろうと予測できます。
結果、マンガAの似た作品として「バトル」の要素を強くもち「刀剣」要素もあるマンガBを算出します。
実際には他の計算手法の利用やスコアのBoostingなどを行っていますが、
このようなステップで、本の要素の抽出と類似性の算出をしています。
検索方法とシステム構成
本のベクトル化やその計算方法について説明しましたが、ここでは実際のシステムに落とし込んだ構成などについて紹介します。
主だったものとして以下を利用しています。
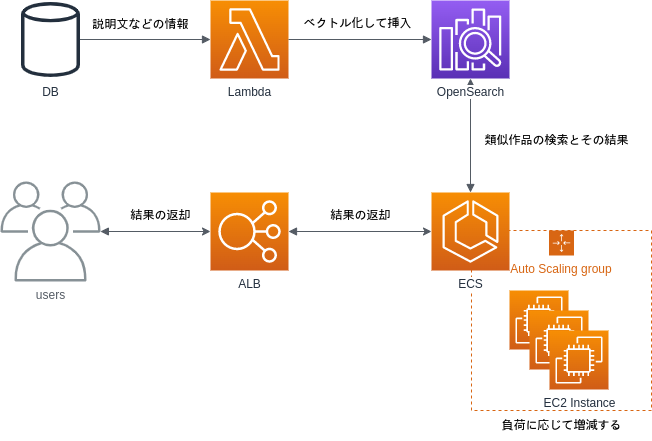
- AWS Lambda: 本のベクトル化などの算出に利用
- AWS ECS: APIサーバーとして
- OpenSearch: 書籍間の類似度の計算と絞り込みのため
今回は、運用上の観点からAWSのマネージドサービスを優先的に選択しています。
簡単に、どのような利用をしているか説明します。
本のベクトル化
まず、本のベクトルの処理は、日々多くの書籍を扱う関係上、AWS Lambdaを利用しています。
AWS Lambdaの同時実行を利用することで、数分間に数万件のベクトル化を行っています。
実際には、以下の3フェーズにわけて、処理できるようにしています。
- 説明文の形態素解析
- 説明文のベクトル化
- 要素との類似度の算出とDBへの挿入
また、これらの処理結果は都度S3に保存することで、
途中の処理で失敗しても、中断箇所からやり直せるようにしています。
類似作品の検索
次に、ベクトル化した本同士の類似度の計算には、OpenSearchを利用しました。
OpenSearchの持っているKNN近傍検索によって、類似度の計算をしています。
さらに、ビジネス要件にそった絞り込みに関しても、OpenSearchの検索機能を利用しています。
そのため、一度のリクエストでビジネス要件にそった類似作品の抽出を行えるようにしています。
検索API
最後に、いままでの機能を外部に提供するためのAPIについて説明します。
利用状況に応じたスケールなどの運用上の観点から、AWS ECSを利用しています。
スケールに関しては、ECS キャパシティープロバイダーとEC2 Auto ScaringGroupを利用しています。
これらを利用することで、タスクの負荷状況に応じてタスクのスケールイン/スケールアウトから、
EC2インスタンスのスケールイン/スケールアウトまでを自動で行えます。
これにより、必要なタスクの増減に伴った、インスタンスの増減に繊細な注意を払う必要がなくなりました。
おかげで、一見するとシンプルな構成にできたのではないかと考えています。
最後に
本機能は、よりお客様が本と出会える機会を増やせないかという考えを元に開発が進められました。
未熟な部分もありますが、「お、こんな本があったのか」などの本との出会いの一助となれれば幸いです。