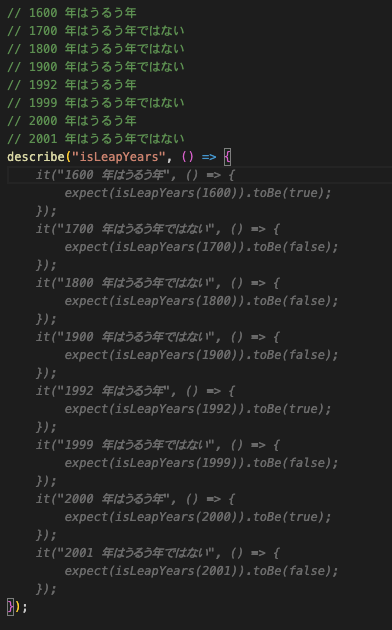
自己紹介
株式会社ブックリスタでエンジニアをしている城、椛澤、尾崎と申します。
私たちは日頃の主業務が異なりますので、それぞれ簡単に紹介させていただきます。
- 城 :スマートフォンアプリ「YOMcoma」の開発
- 椛澤:電子書籍ストアのプロジェクトマネージャー
- 尾崎:電子書籍関連システムのプロジェクトマネージャー
活動概要
プロジェクト発足の経緯
「NFT」というワードについて、近年耳にする機会が増えています。
ブックリスタでは「エンジニアラボ」という取り組みを実施しており、
その中で「NFT」をテーマに1年間研究し、ブックリスタでの「NFT」の活用可能性を模索しました。
エンジニアラボとは
業務とは直接関係しない研究開発プロジェクトを行うことができる制度です。
有志で集まったメンバーが業務時間の最大20%を使い、1年間テーマに沿って研究開発することで、
自己研鑽を高めつつ、成果によってはサービス化に繋がることがあります。
- 2023/1/30 公開の「コミックの類似性の算出とそのシステム構成について」でご紹介した「似た商品を探す」機能が、エンジニアラボの研究成果によってサービス化されました
NFTとは
NFTは非代替性トークン(Non-Fungible Token)の略称で、電子データに一意のトークンを付加することで
電子データに固有の価値をもたらすことができます。
画像、動画、音声はもちろん、チケットやコミュニティへの参加権など本来複製可能なデータに対して一意のアイテムとして扱うことができます。
トークン自体はブロックチェーン上に記録されるため、システム構成としてはブロックチェーンを中心としたシステム構成になります。

活動内容
今回参加したメンバーは全員NFTおよびブロックチェーンの開発未経験者でした。
そのため、まずは座学による知識獲得から開始しましたが、実際に手を動かさないと得られない成果もあります。
ある程度の知識を獲得したところで、実装に向けてより具体的にサービスにアクセスしてきたユーザーが、特定のNFTを所有しているのかを確認する方法を調査しました。
調査結果をふまえてサービス案の検討をしていきました。
サービス案
「もしブックリスタがカントリークラブを始めたら」というテーマを設け、NFTで発行した会員証を保持しているユーザーだけが入場できるサービスと仮定して進めていきます。
アプリケーション概要
今回作成するアプリケーションのシステム構成イメージ図です。

今回作成するアプリケーションはカントリークラブアプリと記載しました。
NFT Gardenを使ってPolygon(Ethreumのサイドチェーン)に独自のコントラクトを作成し、会員証に見立てたNFT(以降、会員証NFT)を複数発行しました。
PolygonやEthereumにおけるNFTとはERC721規格のトークンを指します。
ERC721のIF仕様はOpenZeppelinのドキュメントに記載があります。
これによるとownerOfを叩けば所有者のaddress、すなわちWalletIDを得られることがわかりました。
ではownerOfはどう叩くのか、調べるとRPCプロバイダーがブロックチェーンにリクエストを行いレスポンスを返してくれることが分かったので、今回はAnkrというRPCプロバイダーを使ってみます。
ユーザーを一意に特定するにはWeb3Authを使用します。
GoogleアカウントやSNS等で認証が行え、同じアカウントで認証すれば常に同じ一意の秘密鍵が得られます。
Web3Authで得た秘密鍵をPolygonで使用可能なEthereumAddressに変換し、WalletIDとして使用します。
EthereumAddressへの変換はハッシュ関数を使用するため、同じ秘密鍵を元にした場合は何度作成しても同じEthereumAddressが得られます。
実装
開発環境
プロジェクト作成
- Visual Studio Codeを開き
shift + command + pでFlutter new Project → Application の順に選択
- プロジェクトを配置するディレクトリを選択
- 任意のプロジェクト名を入力する
Web3Authでのウォレット認証
Web3AuthのFlutterSDKに実装手順の記載がありますが、それだけでは動かなかったので実際に動作確認した手順を記載します。
Web3AuthのSDKを入れる
- 作成したプロジェクト直下で
flutter pub add web3auth_flutter
- Web3AuthのFlutterSDKをインストール
flutter pub add web3auth_flutter
- web3dartをインストール
flutter pub add web3dart
./android/app/build.gradleのtargetSdkVersionを33に変更./android/app/build.gradleのcompileSdkVersionを24に変更./android/build.gradleのrepositories {}にmaven { url "https://jitpack.io" }追加./android/app/src/main/AndroidManifest.xmlの<manifest>直下に下記を追加
<uses-permission android:name="android.permission.INTERNET" />
./ios/Runner.xcworkpaceをXcodeで開きFile→Add Packagesを開く- 右上の検索窓に
https://github.com/web3auth/web3auth-swift-sdkを入れweb3auth-swift-sdkでadd Package
./ios/Runner.xcodeproj/project.pbxprojのIPHONEOS_DEPLOYMENT_TARGET3箇所を14.0に変更./ios直下でpod install
Web3AuthのDeveloper Dashboardに登録
Web3AuthのDeveloper Dashboardにプロジェクトを作成しスキーマを登録することで、認証完了後にFlutterアプリ側で認証情報を得る事ができます。

- Developer Dashboardにサインアップ
- サイドバーの
Plug and playを開く(画像①)
Create Projectで任意プロジェクト名を入力しTestnetプロジェクトを作成(画像②)- 作成したプロジェクトを選択し
Add a new whitelist URLにAndroid用とiOS用のURLを登録(画像③)
- Android:
{SCHEME}://{YOUR_APP_PACKAGE_NAME}
- {SCHEME}は任意文字列
- {YOUR_APP_PACKAGE_NAME}はAndroidManifest.xmlのpackageに記載されたもの
- iOS:
{bundleId}://openlogin
- {bundleId}は任意文字列
- ClientIDはコピーしておく(画像④)
- Flutterにスキーマを登録 (SCHEMEとYOUR_APP_PACKAGE_NAMEはwhitelist URLに登録した内容へ置換)
./android/app/src/main/AndroidManifest.xmlの<intent-filter>直下に下記を追記
<data android:scheme="{SCHEME}" android:host="{YOUR_APP_PACKAGE_NAME}" android:path="/auth" />
./ios/Runner/Info.plist4行目付近の<dict>と書かれた直後に下記を追加
<key>FlutterDeepLinkingEnabled</key>
<true/>
<key>CFBundleURLTypes</key>
<array>
<dict>
<key>CFBundleTypeRole</key>
<string>Editor</string>
<key>CFBundleURLName</key>
<string>web3auth</string>
<key>CFBundleURLSchemes</key>
<array>
<string>{bundleId}</string> // Web3Auth dashboard で入力した内容に置換
</array>
</dict>
</array>
実処理を実装する
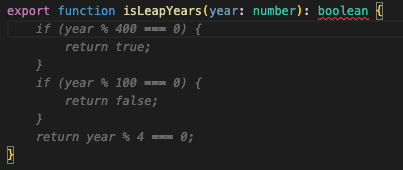
./lib/main.dartをを下記の通り修正しflutter runで実行してみましょう。
import 'dart:io';
import 'package:flutter/material.dart';
import 'package:web3auth_flutter/enums.dart';
import 'package:web3auth_flutter/input.dart';
import 'package:web3auth_flutter/web3auth_flutter.dart';
import 'package:web3dart/credentials.dart';
void main() {
runApp(const MyApp());
}
class MyApp extends StatelessWidget {
}
class MyHomePage extends StatefulWidget {
}
class _MyHomePageState extends State<MyHomePage> {
@override
void initState() {
super.initState();
Uri redirectUrl;
if (Platform.isAndroid) {
redirectUrl = Uri.parse('{SCHEME}://{HOST}/auth');
} else if (Platform.isIOS) {
redirectUrl = Uri.parse('{bundleId}://openlogin');
} else {
throw UnKnownException('Unknown platform');
}
await Web3AuthFlutter.init(Web3AuthOptions(
clientId: "XXXXXXX",
network: Network.testnet,
redirectUrl: redirectUrl));
}
Future<void> login() async {
final result = await Web3AuthFlutter.login(LoginParams(
loginProvider: Provider.google,
mfaLevel: MFALevel.DEFAULT,
));
final credentials = EthPrivateKey.fromHex(result.privKey ?? "");
print(result.userInfo);
print('authenticated WalletID: ${credentials.address.hex}');
}
@override
Widget build(BuildContext context) {
return Scaffold(
appBar: AppBar(
title: Text(widget.title),
),
body: Container(),
floatingActionButton: FloatingActionButton(
onPressed: login,
tooltip: 'Increment',
child: const Icon(Icons.add),
),
);
}
}
画面に表示されたFABを押し、自身のGoogleアカウントで認証すると、Flutterのログに自身のGoogleアカウント情報やWalletIDが表示されました。
簡単な解説です。
StatefulWidgetの生成時に呼ばれるinitState()でWeb3AuthFlutter.init()を呼び出すことで初期化しています。
初期化時のパラメーターにredirectUrlを渡していますが、これはDeveloper Dashboardでホワイトリスト登録したURLと同じ文字列です。
ホワイトリスト登録したURLと同じURLが指定されているのにリダイレクトされない場合は下記を確認してみてください。
- iOS:
./ios/Runner/Info.plistに設定したスキーマ
- Android:
./android/app/src/main/AndroidManifest.xmlに設定したスキーマ
会員証NFTの保持確認
会員証NFTを持っている人だけが入場できるサービスを作るので、ユーザーが会員証NFTを持っているかを確認する処理を実装する必要があります。
Web3Auth認証で得たユーザー情報から、所有するNFTの一覧が取得できるのでは…と少し期待しましたができないようです。
ここでは前述のRPCプロバイダーAnkrを使用して、Polygonから会員証NFT所有者のWalletIDを取得していきます。
PolygonのNFTであるERC721規格のトークンに関する情報を得るには、RPCを介してコントラクト関数が記述されたABIというJSON形式のインターフェースを使用します。
複数存在する会員証NFTの所有者が1つでも認証ユーザーのWalletIDと一致すれば、会員証NFTの所有者であると証明できます。
実装
認証時に作成したlogin()を下記に変更して実行してみます。
Future<void> login() async {
final result = await Web3AuthFlutter.login(LoginParams(
loginProvider: Provider.google,
mfaLevel: MFALevel.DEFAULT,
));
final credentials = EthPrivateKey.fromHex(result.privKey ?? "");
print('authenticated WalletID: ${credentials.address.hex}');
const contractAddress = "0x{contractAddress}";
final client = Web3Client("https://rpc.ankr.com/polygon", http.Client());
const erc721abi =
'[{"anonymous":false,"inputs":[{"indexed":true,"internalType":"address","name":"owner","type":"address"},{"indexed":true,"internalType":"address","name":"approved","type":"address"},{"indexed":true,"internalType":"uint256","name":"tokenId","type":"uint256"}],"name":"Approval","type":"event"},{"anonymous":false,"inputs":[{"indexed":true,"internalType":"address","name":"owner","type":"address"},{"indexed":true,"internalType":"address","name":"operator","type":"address"},{"indexed":false,"internalType":"bool","name":"approved","type":"bool"}],"name":"ApprovalForAll","type":"event"},{"anonymous":false,"inputs":[{"indexed":true,"internalType":"address","name":"from","type":"address"},{"indexed":true,"internalType":"address","name":"to","type":"address"},{"indexed":true,"internalType":"uint256","name":"tokenId","type":"uint256"}],"name":"Transfer","type":"event"},{"inputs":[{"internalType":"address","name":"to","type":"address"},{"internalType":"uint256","name":"tokenId","type":"uint256"}],"name":"approve","outputs":[],"stateMutability":"nonpayable","type":"function"},{"constant":true,"inputs":[],"name":"totalSupply","outputs":[{"name":"","type":"uint256"}],"payable":false,"stateMutability":"view","type":"function"},{"inputs":[{"internalType":"address","name":"owner","type":"address"}],"name":"balanceOf","outputs":[{"internalType":"uint256","name":"balance","type":"uint256"}],"stateMutability":"view","type":"function"},{"inputs":[{"internalType":"uint256","name":"tokenId","type":"uint256"}],"name":"getApproved","outputs":[{"internalType":"address","name":"operator","type":"address"}],"stateMutability":"view","type":"function"},{"inputs":[{"internalType":"address","name":"owner","type":"address"},{"internalType":"address","name":"operator","type":"address"}],"name":"isApprovedForAll","outputs":[{"internalType":"bool","name":"","type":"bool"}],"stateMutability":"view","type":"function"},{"inputs":[],"name":"name","outputs":[{"internalType":"string","name":"","type":"string"}],"stateMutability":"view","type":"function"},{"inputs":[{"internalType":"uint256","name":"tokenId","type":"uint256"}],"name":"ownerOf","outputs":[{"internalType":"address","name":"owner","type":"address"}],"stateMutability":"view","type":"function"},{"inputs":[{"internalType":"address","name":"from","type":"address"},{"internalType":"address","name":"to","type":"address"},{"internalType":"uint256","name":"tokenId","type":"uint256"}],"name":"safeTransferFrom","outputs":[],"stateMutability":"nonpayable","type":"function"},{"inputs":[{"internalType":"address","name":"from","type":"address"},{"internalType":"address","name":"to","type":"address"},{"internalType":"uint256","name":"tokenId","type":"uint256"},{"internalType":"bytes","name":"data","type":"bytes"}],"name":"safeTransferFrom","outputs":[],"stateMutability":"nonpayable","type":"function"},{"inputs":[{"internalType":"address","name":"operator","type":"address"},{"internalType":"bool","name":"_approved","type":"bool"}],"name":"setApprovalForAll","outputs":[],"stateMutability":"nonpayable","type":"function"},{"inputs":[{"internalType":"bytes4","name":"interfaceId","type":"bytes4"}],"name":"supportsInterface","outputs":[{"internalType":"bool","name":"","type":"bool"}],"stateMutability":"view","type":"function"},{"inputs":[],"name":"symbol","outputs":[{"internalType":"string","name":"","type":"string"}],"stateMutability":"view","type":"function"},{"inputs":[{"internalType":"uint256","name":"tokenId","type":"uint256"}],"name":"tokenURI","outputs":[{"internalType":"string","name":"","type":"string"}],"stateMutability":"view","type":"function"},{"inputs":[{"internalType":"address","name":"from","type":"address"},{"internalType":"address","name":"to","type":"address"},{"internalType":"uint256","name":"tokenId","type":"uint256"}],"name":"transferFrom","outputs":[],"stateMutability":"nonpayable","type":"function"}]';
final contract = DeployedContract(
ContractAbi.fromJson(erc721abi, "erc721abi"),
EthereumAddress.fromHex(contractAddress));
int nftTokenIndex = 0;
bool isOwner = false;
while (true) {
try {
final ownerOfResponse = await client.call(
contract: contract,
function: contract.function('ownerOf'),
params: [
BigInt.from(nftTokenIndex),
]);
final ownerWalletID = ownerOfResponse.first.toString();
if (ownerWalletID == credentials.address.hex) {
isOwner = true;
break;
}
nftTokenIndex++;
} catch (e) {
break;
}
}
print("isOwner: $isOwner");
}
ユーザーに会員証NFTを転送する前後で実行するとログのisOwnerの値が意図通りに変わる事が確認できました。
今回はWeb3Client()のパラメータにPolygon向けRPCのURLが設定されていますが、別のチェーンを使用する場合こちらに各エンドポイントが記載されていますので参照ください。
その後のwhileブロック内では下記箇所でownerOf()を実行してNFTの所有者を取得し、認証したWalletIDのcredentials.address.hexと一致するかをみています。
今回で一番大事なところです。
final ownerOfResponse = await client.call(
contract: contract,
function: contract.function('ownerOf'),
params: [
BigInt.from(nftTokenIndex),
]);
if (ownerWalletID == credentials.address.hex) {
最後に
ブロックチェーンを取り巻く環境がめまぐるしく変化していること、筆者らの知見が浅かったことにより、こんなにコンパクトな実装にはふさわしくないであろう時間がかかりました。
時間がかかった大きな要因は、下記3点が大きかったと感じています。
- 開発目線で調べると、「コントラクト」とは何を指すのか、ERC721のIFを叩くには、など調べることが多いが当初検索するキーワードがわからなかった
- 情報が古い記事を見て実装してうまく動かないこと
- 公式のページであってもリンク切れがあるなど、正しい仕様が不明なケースも存在した
この記事の内容が、これからアプリ開発をされる方の何かしらのヒントになれば幸いです。

 (DALL·E 2 によって作成された様々なタッチの画像)
(DALL·E 2 によって作成された様々なタッチの画像)